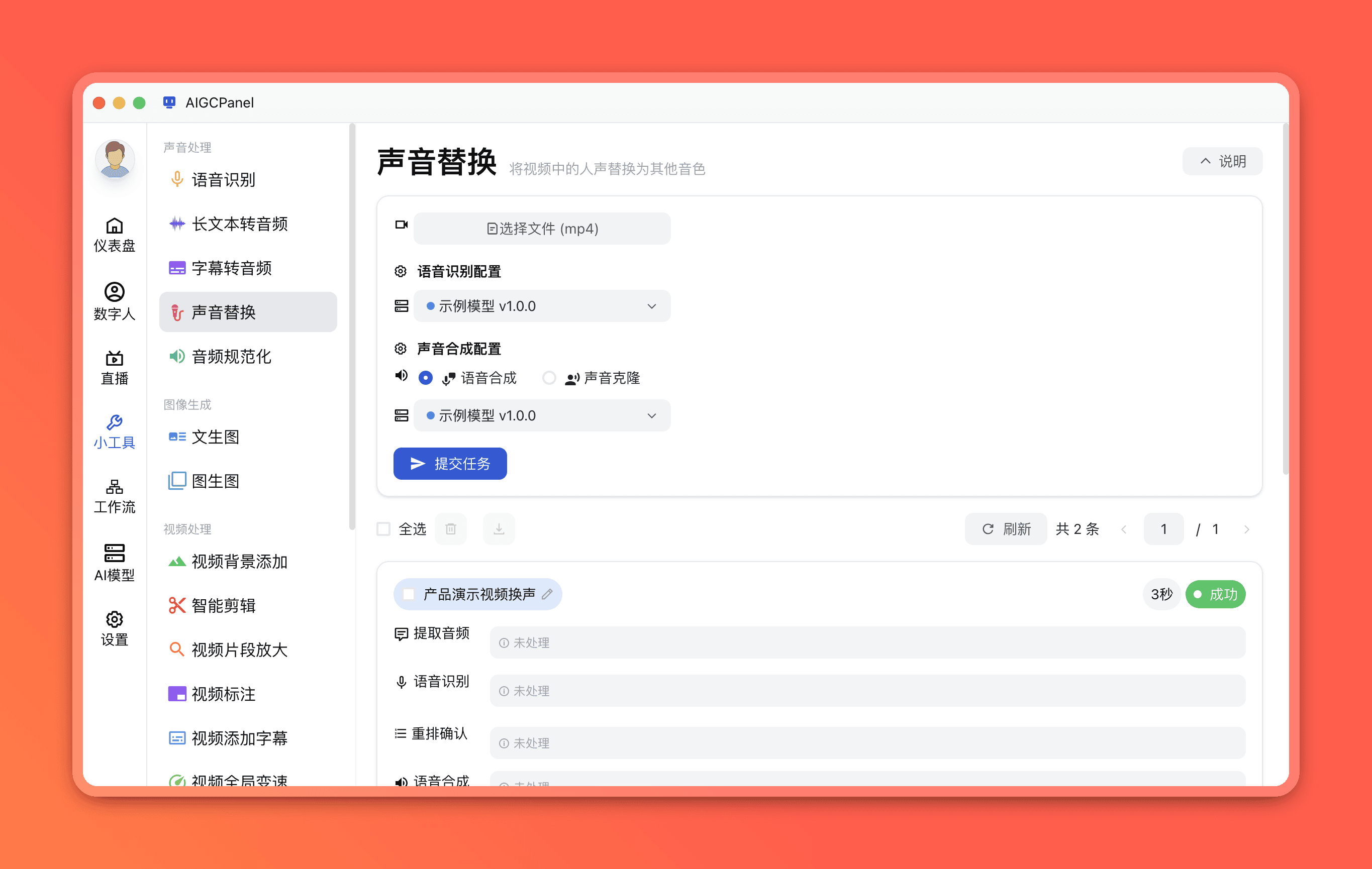
提取视频中的原声音,经过语音识别后,用指定音色重新合成声音并替换回视频,实现声音的无缝替换。
使用步骤
- 打开软件,点击左侧导航栏「小工具」,在声音处理分组中选择「声音替换」
- 点击「选择视频」,上传需要替换声音的视频文件
- 选择语音识别模型和声音合成模型及音色(需提前在「服务器」页面配置)
- 点击「开始处理」提交任务
任务处理分为三个阶段:
-
提取并识别:从视频中提取音轨,使用语音识别转为文字
-
确认文本:查看识别结果,可对文字内容进行修改
-
合成替换:用新音色重新合成语音并替换到视频中
- 任务完成后点击「下载」保存处理后的视频文件
注意事项
- 需要同时配置语音识别模型和声音合成模型
- 识别结果可编辑,修改后再合成可纠正识别错误
- 最终声音与原视频时长保持一致
- 支持批量选择多条记录进行删除或下载

