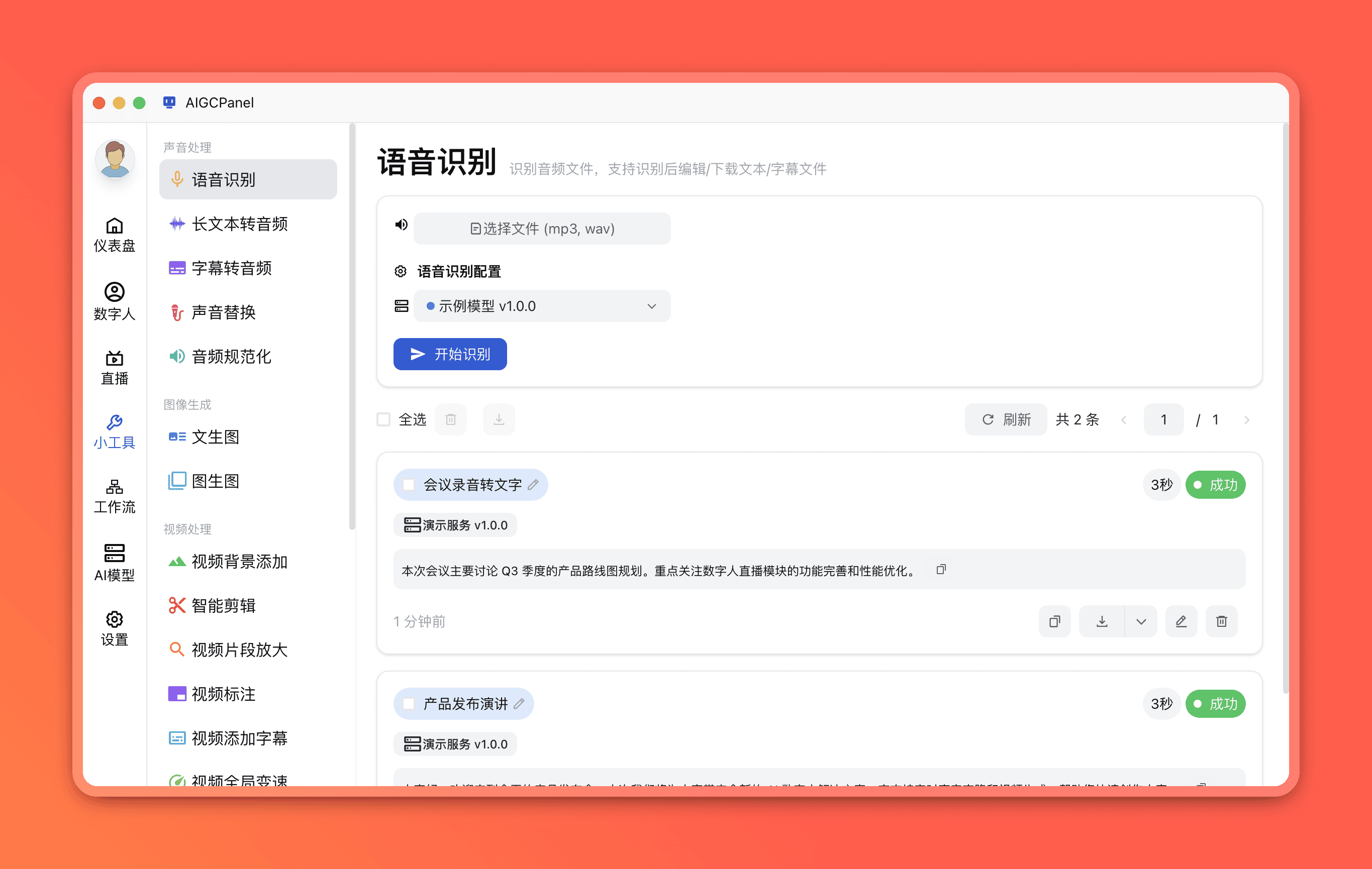
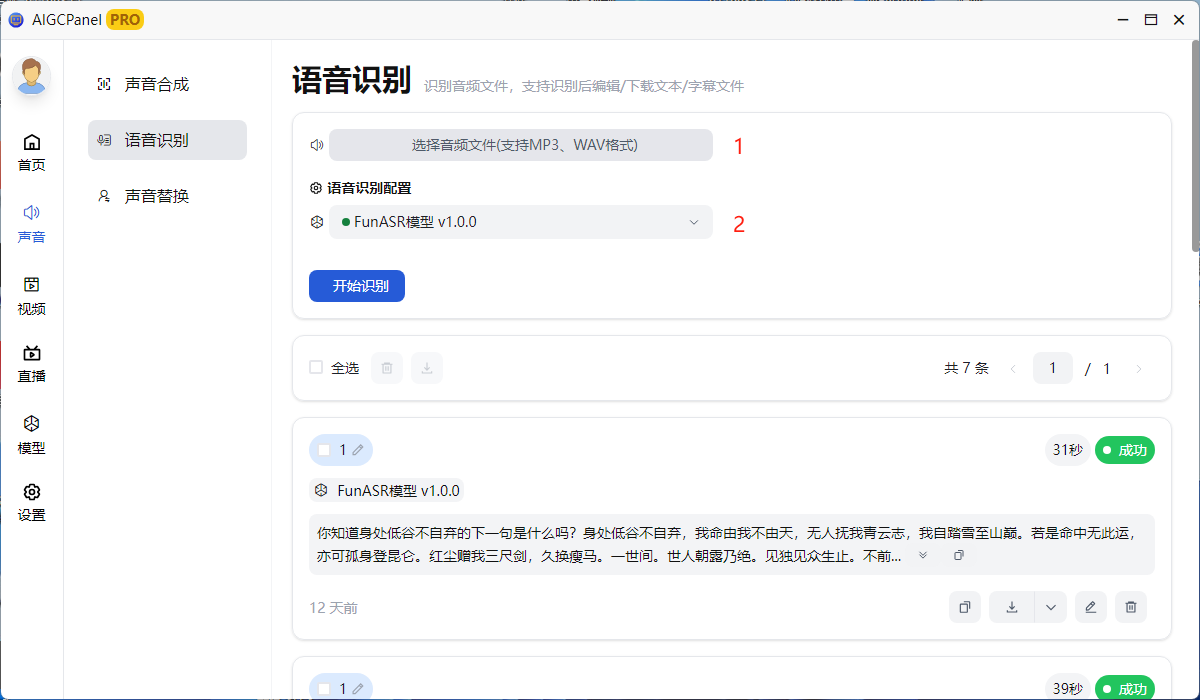
上传音频文件(支持 MP3、WAV 格式)
选择语音识别模型(支持本地模型、云端模型)
点击「开始识别」
识别完成后,可查看带时间轴的文字结果,支持导出为 SRT 字幕文件。
小工具中还提供了「声音替换」功能,可将识别结果重新用 TTS 合成并替换原视频音轨。
QQ扫一扫联系
点击联系
2726531257
微信扫一扫联系
微信扫一扫加群